Embodied-AI models often employ off the shelf vision backbones like CLIP to encode their visual observations. Although such general purpose representations encode rich syntactic and semantic information about the scene, much of this information is often irrelevant to the specific task at hand. This introduces noise within the learning process and distracts the agent's focus from task-relevant visual cues. Inspired by selective attention in humans—the process through which people filter their perception based on their experiences, knowledge, and the task at hand—we introduce a parameter-efficient approach to filter visual stimuli for embodied-AI. Our approach induces a task-conditioned bottleneck using a small learnable codebook module. This codebook is trained jointly to optimize task reward and acts as a task-conditioned selective filter over the visual observation. Our experiments showcase state-of-the-art performance for Object Goal Navigation and Object Displacement across 5 benchmarks, ProcTHOR, ArchitecTHOR, RoboTHOR, AI2-iTHOR, and ManipulaTHOR. The filtered representations produced by the codebook are also able to generalize better and converge faster when adapted to other simulation environments such as Habitat. Our qualitative analyses show that agents explore their environments more effectively and their representations retain task-relevant information like target object recognition while ignoring superfluous information about other objects.
Conventional embodied-AI frameworks usually employ general-purpose visual backbones like CLIP to extract the
visual representations from the input. Such representations capture an abundance of details and a
significant amount of task-irrelevant information.
For example, to find a specific object in a house, the agent doesn't need to know about other distractor
objects in the agent’s view, about their colors, materials, attributes, etc. These distractions introduce
unnecessary noise into the learning process, distracting the agent’s focus away from more pertinent visual cues.
We draw from the substantial body of research in cognitive psychology to induce selective task-specific
representations that filter irrelevant sensory input and only retain the necessary stimuli.
We introduce a compact learnable module that decouples the two objectives in embodied-AI tasks across different
parameters in the network:
Bottlenecking the task-conditioned embeddings using our codebook module results in significant improvements over the non-bottlenecked representations across a variety of Embodied-AI benchmarks. We consider Object Goal Navigation (navigate to find a specific object category in a scene) and Object Displacement (bringing a source object to a destination object using a robotic arm) across 5 benchmarks (ProcTHOR, ArchitecTHOR, RoboTHOR, AI2-iTHOR, and ManipulaTHOR).
Introducing New Metrics for Object Navigation. We present Curvature (k) defined as
| Benchmark (Object Goal Navigation) | Model | SR(%) ▲ | EL ▼ | Curvature ▼ | SEL ▲ |
|---|---|---|---|---|---|
| ProcTHOR-10k (test) | EmbCLIP +Codebook (Ours) |
67.70 73.72 |
182.00 136.00 |
0.58 0.23 |
36.00 43.69 |
| ArchitecTHOR (0-shot) | EmbCLIP +Codebook (Ours) |
55.80 58.33 |
222.00 174.00 |
0.49 0.20 |
20.57 28.31 |
| AI2-THOR (0-shot) | EmbCLIP +Codebook (Ours) |
70.00 78.40 |
121.00 86.00 |
0.29 0.16 |
21.45 26.76 |
| RoboTHOR (0-shot) | EmbCLIP +Codebook (Ours) |
51.32 55.00 |
- - |
- - |
- - |
| Benchmark (Object Displacement) | Model | PU(%) ▲ | SR(%) ▲ |
|---|---|---|---|
| ManipulaTHOR | m-VOLE +Codebook (Ours) |
81.20 86.00 |
59.60 65.10 |
The codebook-based embedding transfers across new visual domains without exhaustive fine-tuning. Our codebook bottleneck effectively decouples the process of learning salient visual information for the task from the process of decision-making based on this filtered information. Consequently, when faced with a similar task in a new visual domain, the need for adaptation is significantly reduced. In this scenario, only the modules responsible for extracting essential visual cues in the new domain require fine-tuning, while the decision-making modules can remain fixed. We show our ObjectNav agent trained in AI2THOR simulator can effectively adapt to the Habitat simulator (which is very different in visual characteristics, lighting, textures and other environmental factors) by merely fine-tuning a lightweight Adaptation Module.
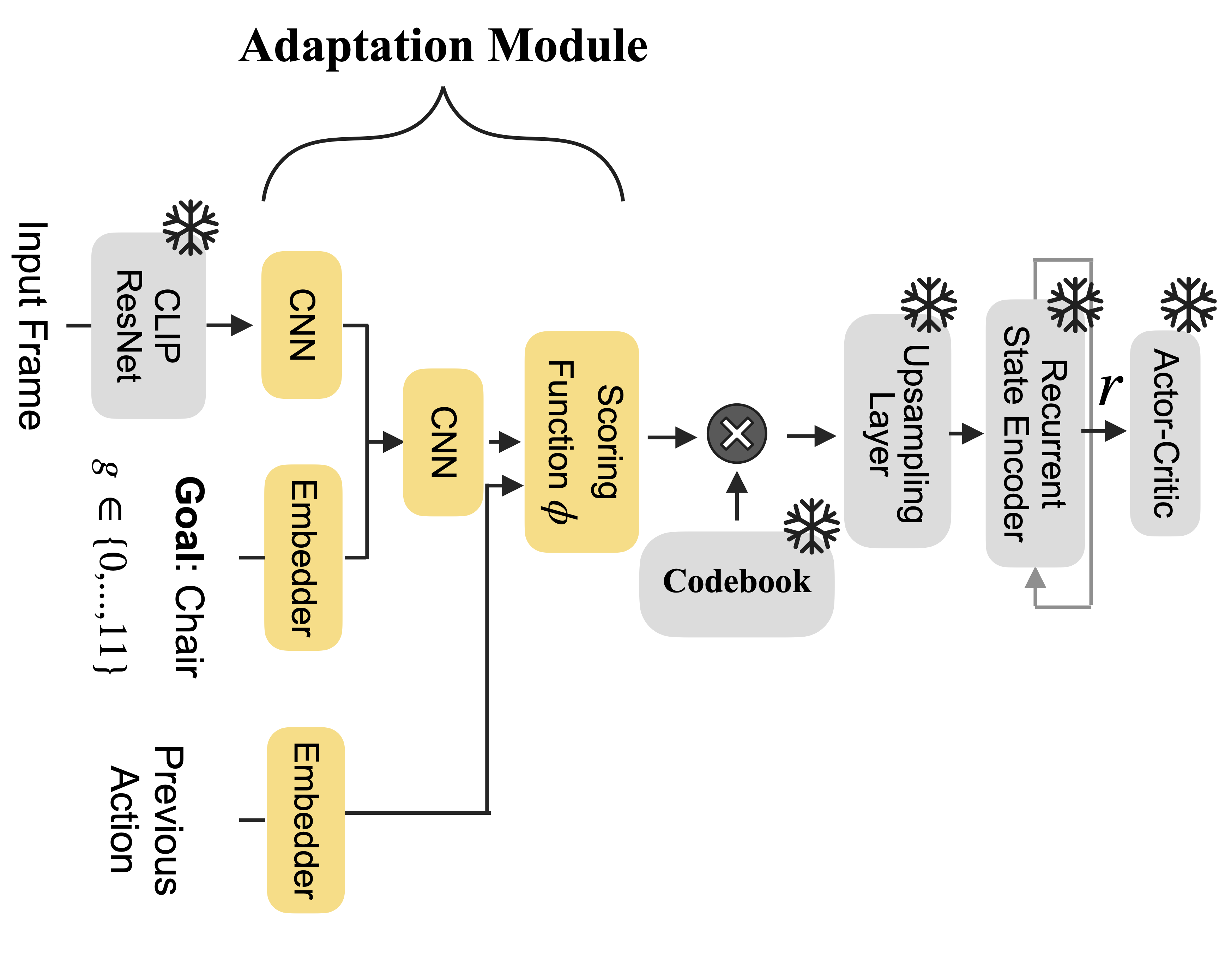
We conduct an analysis (through linear probing, GradCAM attention visualization, and nearest-neighbor retrieval) to explore the information encapsulated within our bottlenecked representations after training for Object Goal Navigation task. The results show that our codebook-bottlenecked representations effectively exclude information related to distracting visual cues and object categories other than the specified goal while only concentrating on the target object and encoding better information about object goal visibility and proximity to the agent.


We conduct a quantitative and qualitative analysis to compare the agent's behavior. The Curvature and Success Weighted by Episode Length (SEL) metrics show that our agent explores more effectively and travels in much smoother paths. Excessive rotations and sudden changes in direction can lead to increased energy consumption and increase the chances of collisions with other objects. Lower SEL achieved by our agent shows that we can find the target object in much fewer steps. The qualitative examples below show that the baseline agent performs lots of redundant rotations.
EmbCLIP-Codebook


EmbCLIP


EmbCLIP-Codebook


EmbCLIP


EmbCLIP-Codebook


EmbCLIP


@article{eftekhar2023selective,
title={Selective Visual Representations Improve Convergence and Generalization for Embodied AI},
author={Eftekhar, Ainaz and Zeng, Kuo-Hao and Duan, Jiafei and Farhadi, Ali and Kembhavi, Ani and Krishna, Ranjay},
journal={arXiv preprint arXiv:2311.04193},
year={2023}
}